Multiprocessing in AWS Lambda
This article will showcase how our team implemented multiprocessing in an AWS Lambda function using Node.js, resulting in a significant speed increase for a high-throughput service used by one of our clients.
Introduction
One of our clients recently approached us with a challenge to improve the speed of a high-throughput data ingestion system. The architecture included a Lambda function that retrieves data from a Kafka topic and stores it in a database. The goal was to find a way to increase the performance of this process.
The first thing we did was tune the AWS Lambda function, adjusting the configuration parameters such as memory allocation to better cater to the processing requirements. We then reviewed the code and identified several operations that were running in sequence but were not required to be executed in this manner, so we started introducing concurrent processing code. We saw a performance improvement; however, the service was still unable to achieve real-time processing during high-demand days.
To further improve performance, we increased the number of partitions in the Kafka topic to allow for more Lambda functions to run concurrently. This approach did work and made the service ingest data faster, but unfortunately, we were unable to increase the number of partitions as desired because doing so would have impacted other services that also consume the same topic.
So, what else could we do to improve the performance of this service without changing the current architecture? We decided to give multiprocessing within a Lambda function a try.
The solution
With every invocation, this Lambda function is triggered with more than a thousand records from the Kafka topic (Event Source Mapping BatchSize) and processes them in parallel. To achieve true parallelism, we utilized the Node.js child process module. In our case, we employed child_process.fork, which is a special case of child_process.spawn() designed specifically to spawn new Node.js processes.
We opted for the Node.js child process module over the Node.js worker threads module because this service needed to handle both CPU-intensive and I/O-intensive operations. If your use case primarily involves CPU-intensive tasks, consider first trying the worker threads module.
Here you can find a simplified example of the first version we used:
File: parent.js
'use strict';
const { fork } = require('child_process');
// Get max child processes from the environment variables, if not provided, it defaults to 3.
const MAX_PROCESSES = process.env.MAX_PROCESSES || 3;
// Child process file path.
const FORK_PATH = 'src/child.js';
module.exports.handler = async (event) => {
try {
// Get the messages to be processed from the event.
const messages = extractMessagesFromEvent(event);
// Get the number of messages per batch.
const batchCount = (messages.length < MAX_PROCESSES) ? 1 : messages.length / MAX_PROCESSES;
// Create the batches
const batches = findSubsets(messages, batchCount);
// Process the batches using the child processes.
await processBatchesInForks({ batches });
} catch (err) {
console.log(`ERROR during execution: ${JSON.stringify(err)}`);
throw err;
}
};
const processBatchesInForks = async ({ batches }) => {
const batchesCount = batches.length;
let responsesReceived = 0;
return new Promise((resolve, reject) => {
for (let id = 0; id < batchesCount; id++) {
const child = fork(FORK_PATH);
child.on('exit', (code) => {
console.log(`Child process exited with code: ${code}`);
// Once all child processes have finished, resolve the promise.
if (++responsesReceived == batchesCount) {
resolve('DONE');
}
});
child.on('message', ({ status }) => {
console.log(`Child process status message: ${status}`);
// We only expect one message from the child process so after receiving it, it disconnects.
child.disconnect();
});
// Send a message to the child.
child.send({ id, batch: batches[id] });
}
})
}
const findSubsets = (array, n) => {
return array.reduce((all, one, i) => {
const ch = Math.floor(i / n);
all[ch] = [].concat((all[ch] || []), one);
return all
}, [])
}
const extractMessagesFromEvent = (event) => {
// HERE, Your code to extra messages from the event payload.
return [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
}File: child.js
"use strict";
// Listening to parent's messages.
process.on("message", async (message) => {
try {
console.log(`Message received from parent: ${JSON.stringify(message)}`);
await processBatch(message.batch);
process.send({ status: "SUCCESS" });
} catch (e) {
console.log(e);
process.send({ status: "FAILED" });
}
});
const processBatch = async (batch) => {
// HERE, Your code to process the batch.
}The above solution significantly increased the speed at which this Lambda function processes each invocation. Our plan was to start using one child process per Lambda function vCPU core, so we began with 5GB Memory for our Lambda function and 3 child processes. The more memory you allocate to your Lambda function, the more vCPU cores will be allocated hence we could increase the child processes count to make this service even faster if needed.
We made it! True; but we wanted to take it even further and refine the code a bit more.
Refactoring the solution
Creating a child process can be time-consuming, so we don’t recommend doing so unless your use case truly requires it. To minimize the performance impact of creating child processes, we decided to reuse them across Lambda invocations, creating them during the first invocation and reusing them throughout the Lambda instance’s lifetime.
We also wanted the number of child processes to be dynamically set based on the vCPU cores allocated to a particular Lambda function. This way, we only needed to change the Lambda memory allocation, and the code would create child processes accordingly.
Here is the refactored code with the dynamic and reusable child processes:
File: parent.js
'use strict';
const os = require("os");
const { fork } = require('child_process');
const cpuData = os.cpus();
console.log('CPU Details', cpuData);
const THREADS_PER_CPU = process.env.THREADS_PER_CPU || 1;
// If Max processes param is passed, then use that value. Otherwise, set it dynamically based on vCPU cores.
const MAX_PROCESSES = process.env.MAX_PROCESSES || cpuData.length * THREADS_PER_CPU;
const FORK_PATH = 'src/child.js';
let childProcesses = [];
const createFork = () => {
const newFork = fork(FORK_PATH);
newFork.on('error', (error) => {
console.log(`Error on child process: ${error}`);
})
return newFork;
}
for (let id = 0; id < MAX_PROCESSES; id++) {
childProcesses.push(createFork());
}
// Removes child processes listeners of each Lambda invocation.
const removeForkEvents = () => childProcesses.forEach(child => { child.removeAllListeners('exit'); child.removeAllListeners('message') });
module.exports.handler = async (event) => {
try {
// Get the messages to be processed from the payload.
const messages = extractMessagesFromEvent(event);
// Get the amount of messages per batch.
const batchCount = (messages.length < MAX_PROCESSES) ? 1 : messages.length / MAX_PROCESSES;
// Create the batches
const batches = findSubsets(messages, batchCount);
// Process the batches using the child processes.
await processBatchesInForks({ batches });
} catch (err) {
console.log(`ERROR during execution: ${JSON.stringify(err)}`);
throw err;
}
};
const processBatchesInForks = async ({ batches }) => {
const batchesCount = batches.length;
let responsesReceived = 0;
return new Promise((resolve, reject) => {
for (let id = 0; id < batchesCount; id++) {
// If a child has exited, then we recreate it.
if (!childProcesses[id]?.connected) {
console.log(`Child #${id} no connected`);
childs[id] = createFork();
}
childProcesses[id].on('exit', (code) => {
console.log(`Child process exited with code: ${code}`);
// In case a child exists without sending a message.
if (++responsesReceived == batchesCount) {
removeForkEvents();
resolve('DONE');
}
});
childProcesses[id].on('message', ({ status }) => {
console.log(`Child process status message: ${status}`);
if (++responsesReceived == batchesCount) {
removeForkEvents();
resolve('DONE');
}
});
// Send a message to the child.
childProcesses[id].send({ id, batch: batches[id] });
}
})
}
const findSubsets = (array, n) => {
return array.reduce((all, one, i) => {
const ch = Math.floor(i / n);
all[ch] = [].concat((all[ch] || []), one);
return all
}, [])
}
const extractMessagesFromEvent = (event) => {
// HERE, Your code to extra messages from the event payload.
return [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
}How can I start using multiprocessing in my AWS Lambda functions?
You can use the above solution code snippet as an example to start leveraging Node.js’s built-in Child Process or Worker Thread modules, or you can use the node-parallelizer library.
That’s right, we’ve created a library to help you with the multiprocessing implementation. This library allows you to choose between two parallelizers (Child Processes or Worker Threads). Depending on your use case, you can use one, the other, or even both simultaneously.
Example using Node-Parallelizer library
You can find all the necessary details on the node-parallelizer library GitHub page, but I’ll provide an overview of the basic usage here:
File: parent.js
'use strict';
const { Parallelizer, PARALLELIZER_CHILD, PARALLELIZER_THREADS } = require("node-parallelizer");
// Creates a new parallelizer instance.
const parallelizer = new Parallelizer({ type: PARALLELIZER_CHILD, filePath: "/var/task/src/child.js", processBatchFunctionName: 'batchProcessor' });
module.exports.handler = async(event) => {
// Run batch in parallel
const responses = await parallelizer.run(event.Records);
console.log(responses);
};File: child.js
'use strict';
const batchProcessor = ({ batch }) => {
//
// HERE YOUR CODE
//
return { success: true, count: batch.length }
}
module.exports = { batchProcessor }But how does this multiprocessing affect my Lambda function?
It doesn’t change much; it’s just that your code can now truly be executed in parallel. Anyway, a picture is worth a thousand words, isn’t it?
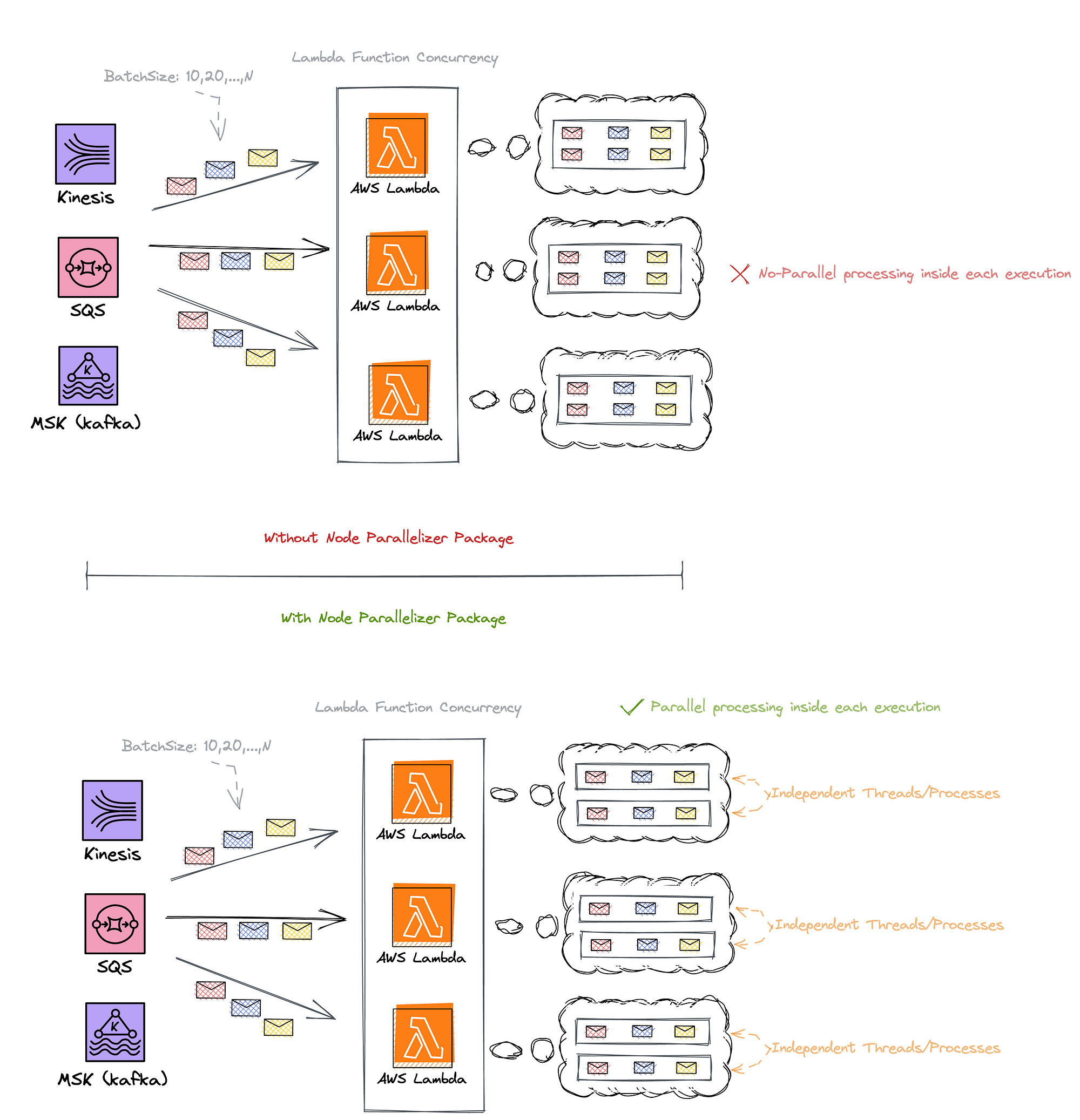
*I know, I know, this is a highly simplified representation of how multiprocessing works, but I wanted to keep it simple and at a high level.
Benchmark
CPU & I/O operations
$ node test/benchmark.js
Child Parallelizer x 18.08 ops/sec
Thread Parallelizer x 15.90 ops/sec
Without Parallelizer x 2.79 ops/sec
Result:
Fastest is Child Parallelizer
Slowest is Without ParallelizerChild + Thread Parallelizers VS JavaScript Promise.All
$ node test/benchmark-2.js
Child + Thread Parallelizers x 16.42 ops/sec
JavaSCript Promise.All x 7.49 ops/sec
Result:
Fastest is Child + Thread Parallelizers
Slowest is JavaSCript Promise.AllConclusion
We’ve just seen how powerful multiprocessing can be and how it can help us speed up our Lambda execution time. We also explored various approaches to multiprocessing, from using Node.js’s built-in modules directly to utilizing a wrapper that simplifies the process. In our benchmark section, we even compared the performance of JavaScript Promise.all with the Node-Parallelizer library.
However, we don’t recommend this approach for every scenario. This can introduce extra complexity to your code, and if you’re not concerned about the performance of your service, it might not be worth the effort.